 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivFusion: A Privacy-preserving Multi-Agent Framework for Harmonizing Distributed Datasets
May 22, 2026The growing availability of clinical data has increased the use of machine learning, yet centralized data aggregation is often infeasible for sensitive health information. Federated Learning (FL) offers a distributed alternative, but its adoption is limited by substantial heterogeneity across institutional datasets, making harmonization a critical but frequently overlooked prerequisite for multi-site analytics. We introduce PrivFusion, a privacy-preserving multi-agent framework that automates the harmonization of structured datasets prior to federated training. PrivFusion uses agents to analyze local data, cluster semantically similar features across sites, and provide iterative transformation recommendations until alignment is achieved. Evaluation across four heterogeneous COVID-19 datasets demonstrates that PrivFusion effectively and efficiently harmonizes multi-site data while substantially reducing manual effort.
Persona-Conditioned Adversarial Prompting: Multi-Identity Red-Teaming for Adversarial Discovery and Mitigation
May 12, 2026Automated red-teaming for LLMs often discovers narrow attack slices, missing diverse real-world threats, and yielding insufficient data for safety fine-tuning. We introduce Persona-Conditioned Adversarial Prompting (PCAP), which conditions adversarial search on diverse attacker personas (e.g., doctors, students, malicious actors) and strategy sets to explore realistic attack scenarios. By running parallel persona-conditioned searches, PCAP discovers transferable jailbreaks across different contexts and generates rich defense datasets with automatic metadata tracking. On GPT-OSS 120B, PCAP increases attack success from 57\% to 97\% while producing 2-6$\times$ more diverse prompts covering varied real-world scenarios. Critically, fine-tuning lightweight adapters on PCAP-generated data significantly improves model robustness (recall: 0.36 $\rightarrow$ 0.99, F1: 0.53 $\rightarrow$ 0.96) with minimal false positives, demonstrating a practical closed-loop approach from vulnerability discovery to automated alignment.
LoMime: Query-Efficient Membership Inference using Model Extraction in Label-Only Settings
Feb 21, 2026Membership inference attacks (MIAs) threaten the privacy of machine learning models by revealing whether a specific data point was used during training. Existing MIAs often rely on impractical assumptions such as access to public datasets, shadow models, confidence scores, or training data distribution knowledge and making them vulnerable to defenses like confidence masking and adversarial regularization. Label-only MIAs, even under strict constraints suffer from high query requirements per sample. We propose a cost-effective label-only MIA framework based on transferability and model extraction. By querying the target model M using active sampling, perturbation-based selection, and synthetic data, we extract a functionally similar surrogate S on which membership inference is performed. This shifts query overhead to a one-time extraction phase, eliminating repeated queries to M . Operating under strict black-box constraints, our method matches the performance of state-of-the-art label-only MIAs while significantly reducing query costs. On benchmarks including Purchase, Location, and Texas Hospital, we show that a query budget equivalent to testing $\approx1\%$ of training samples suffices to extract S and achieve membership inference accuracy within $\pm1\%$ of M . We also evaluate the effectiveness of standard defenses proposed for label-only MIAs against our attack.
In-Context Bias Propagation in LLM-Based Tabular Data Generation
Jun 11, 2025Large Language Models (LLMs) are increasingly used for synthetic tabular data generation through in-context learning (ICL), offering a practical solution for data augmentation in data scarce scenarios. While prior work has shown the potential of LLMs to improve downstream task performance through augmenting underrepresented groups, these benefits often assume access to a subset of unbiased in-context examples, representative of the real dataset. In real-world settings, however, data is frequently noisy and demographically skewed. In this paper, we systematically study how statistical biases within in-context examples propagate to the distribution of synthetic tabular data, showing that even mild in-context biases lead to global statistical distortions. We further introduce an adversarial scenario where a malicious contributor can inject bias into the synthetic dataset via a subset of in-context examples, ultimately compromising the fairness of downstream classifiers for a targeted and protected subgroup. Our findings demonstrate a new vulnerability associated with LLM-based data generation pipelines that rely on in-context prompts with in sensitive domains.
Privacy-Preserving Model and Preprocessing Verification for Machine Learning
Jan 14, 2025



This paper presents a framework for privacy-preserving verification of machine learning models, focusing on models trained on sensitive data. Integrating Local Differential Privacy (LDP) with model explanations from LIME and SHAP, our framework enables robust verification without compromising individual privacy. It addresses two key tasks: binary classification, to verify if a target model was trained correctly by applying the appropriate preprocessing steps, and multi-class classification, to identify specific preprocessing errors. Evaluations on three real-world datasets-Diabetes, Adult, and Student Record-demonstrate that while the ML-based approach is particularly effective in binary tasks, the threshold-based method performs comparably in multi-class tasks. Results indicate that although verification accuracy varies across datasets and noise levels, the framework provides effective detection of preprocessing errors, strong privacy guarantees, and practical applicability for safeguarding sensitive data.
FairSISA: Ensemble Post-Processing to Improve Fairness of Unlearning in LLMs
Dec 12, 2023



Training large language models (LLMs) is a costly endeavour in terms of time and computational resources. The large amount of training data used during the unsupervised pre-training phase makes it difficult to verify all data and, unfortunately, undesirable data may be ingested during training. Re-training from scratch is impractical and has led to the creation of the 'unlearning' discipline where models are modified to "unlearn" undesirable information without retraining. However, any modification can alter the behaviour of LLMs, especially on key dimensions such as fairness. This is the first work that examines this interplay between unlearning and fairness for LLMs. In particular, we focus on a popular unlearning framework known as SISA [Bourtoule et al., 2021], which creates an ensemble of models trained on disjoint shards. We evaluate the performance-fairness trade-off for SISA, and empirically demsontrate that SISA can indeed reduce fairness in LLMs. To remedy this, we propose post-processing bias mitigation techniques for ensemble models produced by SISA. We adapt the post-processing fairness improvement technique from [Hardt et al., 2016] to design three methods that can handle model ensembles, and prove that one of the methods is an optimal fair predictor for ensemble of models. Through experimental results, we demonstrate the efficacy of our post-processing framework called 'FairSISA'.
AUTOLYCUS: Exploiting Explainable AI (XAI) for Model Extraction Attacks against Decision Tree Models
Feb 04, 2023



Model extraction attack is one of the most prominent adversarial techniques to target machine learning models along with membership inference attack and model inversion attack. On the other hand, Explainable Artificial Intelligence (XAI) is a set of techniques and procedures to explain the decision making process behind AI. XAI is a great tool to understand the reasoning behind AI models but the data provided for such revelation creates security and privacy vulnerabilities. In this poster, we propose AUTOLYCUS, a model extraction attack that exploits the explanations provided by LIME to infer the decision boundaries of decision tree models and create extracted surrogate models that behave similar to a target model.
Federated Unlearning: How to Efficiently Erase a Client in FL?
Jul 12, 2022
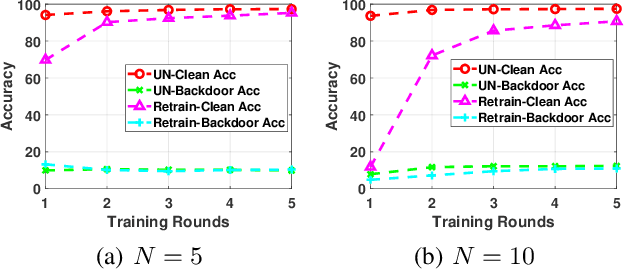
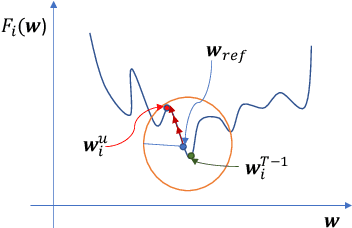
With privacy legislation empowering users with the right to be forgotten, it has become essential to make a model forget about some of its training data. We explore the problem of removing any client's contribution in federated learning (FL). During FL rounds, each client performs local training to learn a model that minimizes the empirical loss on their private data. We propose to perform unlearning at the client (to be erased) by reversing the learning process, i.e., training a model to \emph{maximize} the local empirical loss. In particular, we formulate the unlearning problem as a constrained maximization problem by restricting to an $\ell_2$-norm ball around a suitably chosen reference model to help retain some knowledge learnt from the other clients' data. This allows the client to use projected gradient descent to perform unlearning. The method does neither require global access to the data used for training nor the history of the parameter updates to be stored by the aggregator (server) or any of the clients. Experiments on the MNIST dataset show that the proposed unlearning method is efficient and effective.